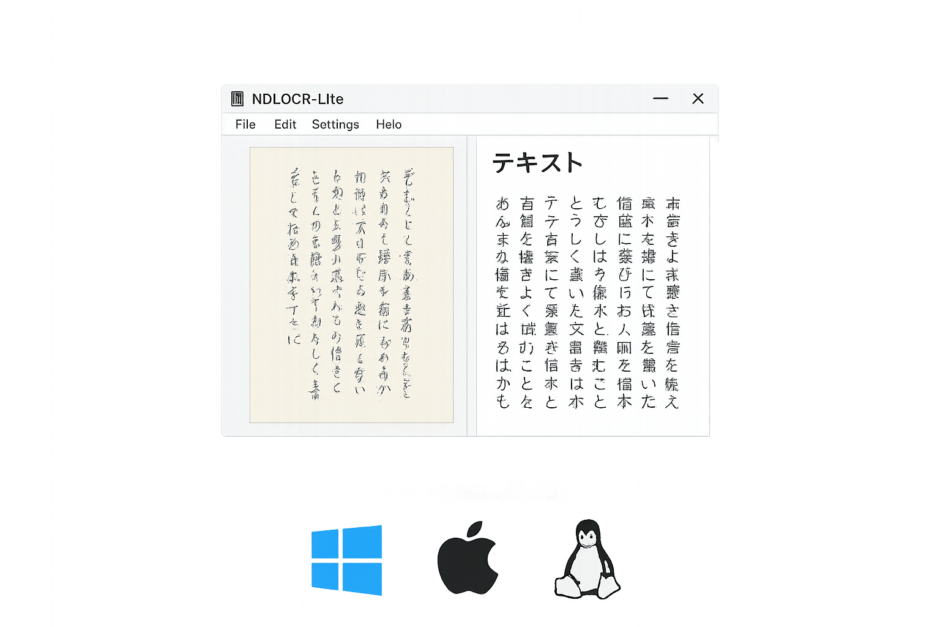


- 国立国会図書館が無料OCRアプリ「NDLOCR-Lite」を公開。日本語・手書き・縦書きに対応したテキスト化ツール
- GPUなしの一般的なノートPCで動作する軽量設計。Windows・Mac・Linux・Web版すべて対応
- 範囲指定OCR(Crop&OCR)やスクリーンキャプチャ直接読み取り(Captureモード)など実用的な機能を搭載
- レイアウト認識にDEIMv2、文字列認識にPARSeqを採用。英語活字にも試験的に対応
- CC BY 4.0ライセンスで完全無料。個人利用から教育・研究・自治体業務まで幅広く活用可能
古い手紙をデジタル化したい。
縦書きの歴史資料をテキストに変換したい。
しかし市販のOCRソフトは日本語の精度が低く、手書きや縦書きはほぼ対応できない——そんな長年の課題に、国立国会図書館が答えを出しました。
NDLOCR-Liteは、日本語の活字・手書き・縦書きに対応した完全無料のOCRアプリ。
GPUなしの一般的なノートPCで動作し、国会図書館が蓄積してきた膨大な資料とノウハウに基づいて開発されています。
NDLOCR-Liteとは何か
NDLOCR-Liteは、国立国会図書館(NDL)が2026年2月24日に公開した軽量OCR(光学文字認識)アプリケーションです。
- 開発元 — 国立国会図書館 NDLラボ
- 対応文字 — 日本語活字、手書き文字(試行的対応)、縦書き、英語活字(試行的対応)
- 対応OS — Windows、Mac、Linux、Web版(ブラウザで利用可能)
- 動作要件 — GPUなしの一般的なノートPCで動作。特殊なハードウェア不要
- ライセンス — CC BY 4.0。完全無料で商用利用も可能
- 技術基盤 — DEIMv2(レイアウト認識)+PARSeq(文字列認識)
たとえるなら、NDLOCR-Liteは「国会図書館の司書がPCに宿った」ようなもの。何百万冊もの蔵書をデジタル化してきた国会図書館の知見が、家庭のノートPCで使える無料アプリに凝縮されています。
主な機能|4つのOCRモード
NDLOCR-Liteは、用途に応じた4つのモードを搭載しています。
- 単一画像処理 — 1枚の画像やPDFから文字を読み取り。最も基本的なモード
- バッチ処理 — フォルダ内の複数画像を一括処理。大量のスキャン画像を効率的にテキスト化
- Crop&OCRモード — 画像内の特定範囲を指定して読み取り。表の一部だけ、特定の段落だけを正確に抽出
- Captureモード — 画面上の任意の領域をキャプチャして直接OCR。PDFビューアーやWebページの内容をそのまま読み取り
特にCaptureモードは画期的です。
画像ファイルとして保存する手間なく、画面に映っているものをそのままテキスト化できる。
古いPDFを表示して範囲選択するだけで、テキストが取得できます。
日本語OCRの課題と解決
日本語のOCRは、英語と比較して格段に難しい技術です。
- 文字種の多さ — ひらがな、カタカナ、漢字(JIS第1〜第4水準で約1万字)、英数字、記号。英語の26文字とは桁違い
- 縦書き・横書き混在 — 同じ文書内に縦書きと横書きが混在する場合がある
- 手書きの多様性 — 日本語の手書きは個人差が大きく、崩し方のパターンが膨大
- ルビ(ふりがな) — 漢字の上に小さな文字が併記される日本語独自の表記
NDLOCR-Liteは、国立国会図書館が何百万冊もの資料をデジタル化してきた実践的なノウハウに基づいて開発されています。学術論文や理論だけでなく、実際の資料で直面した課題を解決してきた経験が、認識精度に反映されています。
活用事例|教育から自治体業務まで
- 歴史資料のデジタル化 — 古文書、古い新聞、明治・大正期の文書をテキスト化。研究者のアクセシビリティ向上
- 図書館蔵書 — 地域図書館の未デジタル化資料のテキスト化。全文検索の実現
- 自治体業務 — 古い行政文書、住民記録のデジタル化。紙からデジタルへの移行を加速
- 教育現場 — 歴史教材の作成、古い教科書のテキスト化
- 個人利用 — 家族の手紙・日記・メモの電子化。思い出の保存
競合との比較
- Google ドキュメントOCR — Google Driveに画像をアップロードしてテキスト化。日本語対応だが縦書き・手書きは弱い
- Adobe Acrobat OCR — 高精度だが有料(月額約2,000円〜)。日本語の縦書きは不完全
- Tesseract OCR — オープンソースの定番。日本語対応はあるが精度に課題。手書き非対応
- NDLOCR-Lite — 日本語特化、手書き・縦書き対応、完全無料、GPUなしで動作
NDLOCR-Liteの圧倒的な優位性は、「日本語に特化した無料OCR」という唯一無二のポジション。国立機関が開発・提供している信頼性と、CC BY 4.0という自由なライセンスの組み合わせは、他に例がありません。
よくある質問(FAQ)
Q. 完全に無料ですか?
はい、完全無料です。
CC BY 4.0ライセンスで公開されており、個人利用・商用利用・教育利用すべて可能です。
ソースコードもGitHubで公開されています。
Q. GPUは必要ですか?
不要です。
一般的なノートPCのCPUで動作するよう軽量化されています。
前身のNDLOCRはGPUが必要でしたが、NDLOCR-Liteではこの制約を解消しています。
Q. 手書き文字の認識精度は?
手書き文字は試行的な対応です。
丁寧に書かれた手書きであれば実用的な精度が期待できますが、極端に崩した文字やくずし字(草書体)は認識率が低下する場合があります。
活字であれば非常に高い精度を示します。
Q. Web版はどこから使えますか?
NDLラボの公式サイトからアクセスできます。
インストール不要で、ブラウザ上で画像をアップロードしてOCR処理が可能です。
デスクトップ版はGitHubからダウンロードできます。
まとめ
この記事のポイントを振り返りましょう。
- NDLOCR-Liteは国立国会図書館が開発した無料OCR。日本語・手書き・縦書きに対応
- GPUなしの一般的なノートPCで動作。Windows・Mac・Linux・Web版に対応
- Crop&OCRモードやCaptureモードなど、4つの実用的なOCRモードを搭載
- DEIMv2+PARSeqの最新技術基盤。CC BY 4.0ライセンスで完全無料・商用利用可能
- 歴史資料・図書館蔵書・自治体業務・個人の思い出まで、幅広い活用が可能
日本語のOCRは長年「高価で精度が低い」という課題を抱えてきました。
NDLOCR-Liteは、国立国会図書館という日本最大の知のアーカイブが培ったノウハウを、無料で誰にでも開放するプロジェクトです。
古い資料、手書きのメモ、縦書きの文書——デジタル化をあきらめていたものが、今、テキストに変わります。
参考文献
- NDLラボ. (2026). NDLOCR-Liteの公開について. NDLラボ
- NDLラボ. (2026). NDLOCR-Liteの使い方. NDLラボ
- GitHub. ndl-lab/ndlocr-lite. GitHub
- GIGAZINE. (2026). 無料で日本語・手書き・縦書きもテキスト化できる国立国会図書館のOCRアプリ「NDLOCR-Lite」. GIGAZINE
- カレントアウェアネス・ポータル. (2026). 国立国会図書館(NDL)、OCRソフトウェア「NDLOCR-Lite」を公開. カレントアウェアネス
こんな時代だから遊んで学びたい

AIを学ぶオンラインサロン「AIフレンズ」では、生成AIを楽しく、どこよりも優しく学べる環境をご用意しております。
毎週開催されるオンラインセッションでは、リアルタイムで学び合える機会を提供しています。 さらに、月に一度のオフラインイベントでは、メンバー同士が直接交流し、アイデアや知識を深めることができます。
「AIフレンズ」の仲間とともに、新しい価値を創造し、可能性を広げてみませんか?
一緒に学び、成長しながら、生成AIを使いこなす力を身につけましょう!








Excellent, what a weblog it is! This webpage gives
useful data to us, keep it up.
References:
Lollybet App secure.jugem.jp
References:
Lollybet Casino Sicherheit http://share.pho.to/away?to=https://lollybet.com.de&id=ACBj7&t=9BpgEvc